
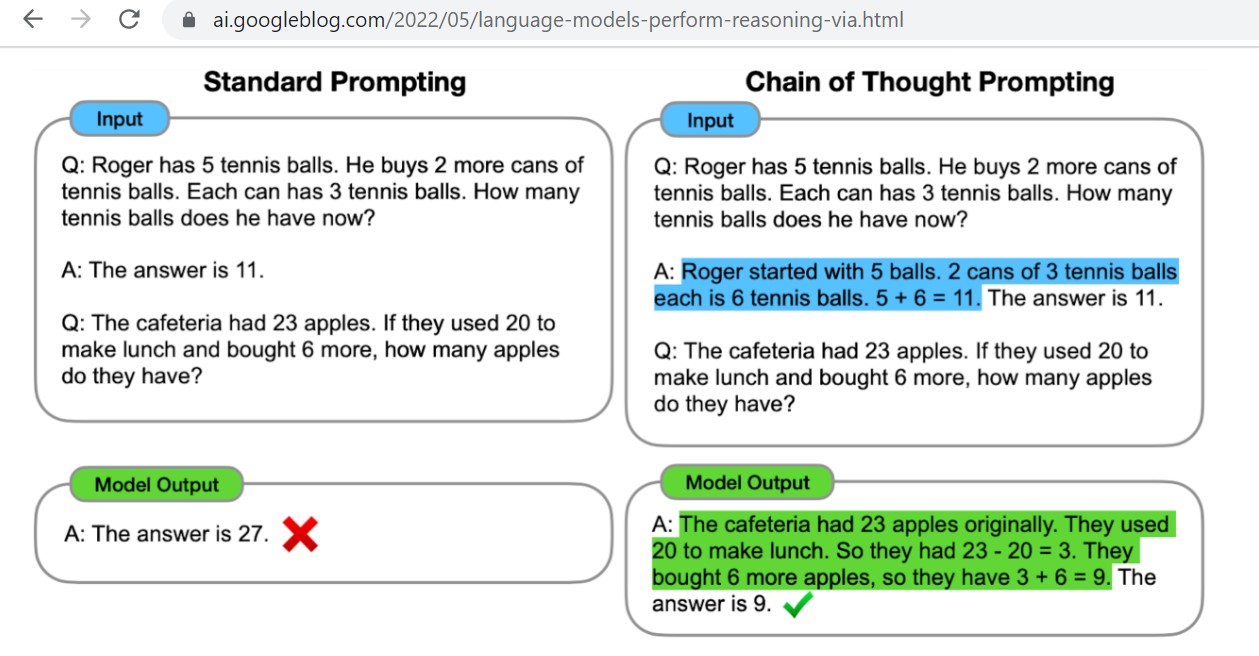
For those of you keeping up-to-speed with the latest developments, innovations and breakthroughs in AI, you’re probably familiar with chain of thought (CoT) prompt engineering methods that improve a language model’s performance scores as measured by a collective of standardized testing systems such as the US medical board exam, US bar examines and various other flavors of intelligence testing.
In a Google Research paper from May 11, 2022, it explains how by training the model on CoT prompt completion logic actually improves reasoning capabilities by breaking down a multiple step process into several individual steps, reinforcing it’s learned understandings and common logic reasoning.
This type of chain of thought prompting indeed improves a model’s ability to accurately predict the next token.
Therefore, it seems like GPT brain should use the chain of thoughts training technique as a an effective methodology and LLM training solution to be applied among several other key training methodologies, more specifically, Reinforcement Learning with AI Feedback (RLAIF) and Reinforcement Learning with Human Feedback (RLHF), both of which are proven machine learning techniques for properly labeling & structuring data.
How Chain of Thought Prompting Works
The underlying logic principles demonstrated through Chain of Thought Prompting (CoT) teaches language models to follow a logical sequence of steps in order to better construct it’s reasoning paths.
This improved chain of thought reasoning introduced to AI models through this style of CoT Prompts leads to increased scores by training language models standardized tests and performance tasks.
Chain of thought prompting is a simple and broadly applicable method for improving the ability of language models to perform a number of reasoning tasks. It broadens the range of reasoning tasks that language models can perform and inspires further work on language-based approaches to reasoning.